DLPv2
Extending Deep Latent Particles (DLP)

We extend the definition of a latent particle from the original DLP with additional attributes for a more accurate prediction and to improve the autoencoding performance.
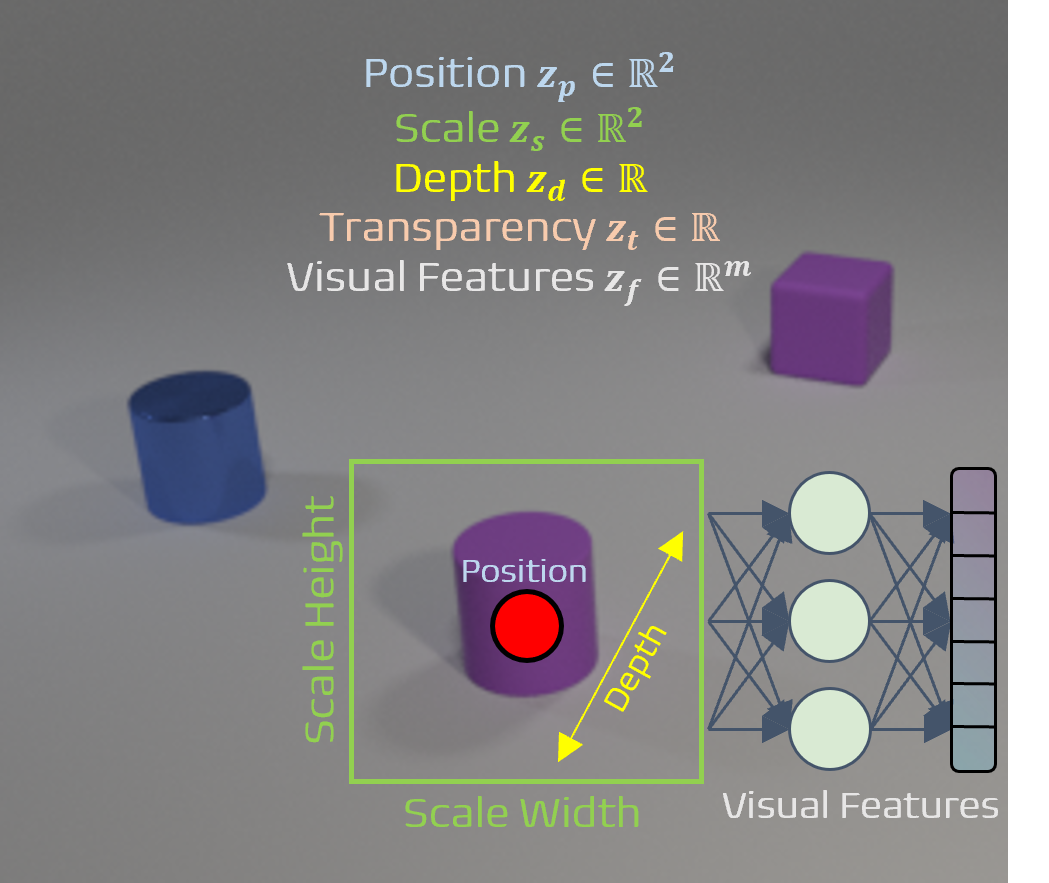
A foreground latent particle \(z = [z_p, z_s, z_d, z_t, z_f] \in \mathbb{R}^{6 + m}\) is a disentangled latent variable composed of the following learned stochastic latent attributes:
- Position \(z_p \sim \mathcal{N}(\mu_p, \sigma_p^2) \in \mathbb{R}^2\)
- Scale \(z_s \sim \mathcal{N}(\mu_s, \sigma_s^2) \in \mathbb{R}^2\)
- Depth \(z_d \sim \mathcal{N}(\mu_d, \sigma_d^2) \in \mathbb{R}\)
- Transparency \(z_t \sim \text{Beta}(a_t, b_t) \in \mathbb{R}\)
- Visual features \(z_f \sim \mathcal{N}(\mu_f, \sigma_f^2) \in \mathbb{R}^m\), where \(m\) is the dimension of learned visual features.
- Background \(z_{\text{bg}} \sim \mathcal{N}(\mu_{\text{bg}}, \sigma_{\text{bg}}^2) \in \mathbb{R}^{m_{\text{bg}}}\), always located in the center of the image and described only by \(m_{\text{bg}}\) latent background visual features.
The architecture design of DLPv2 follows the original design of DLP, where the encoder is modified to account for the new attributes. Please refer to the paper for more details.
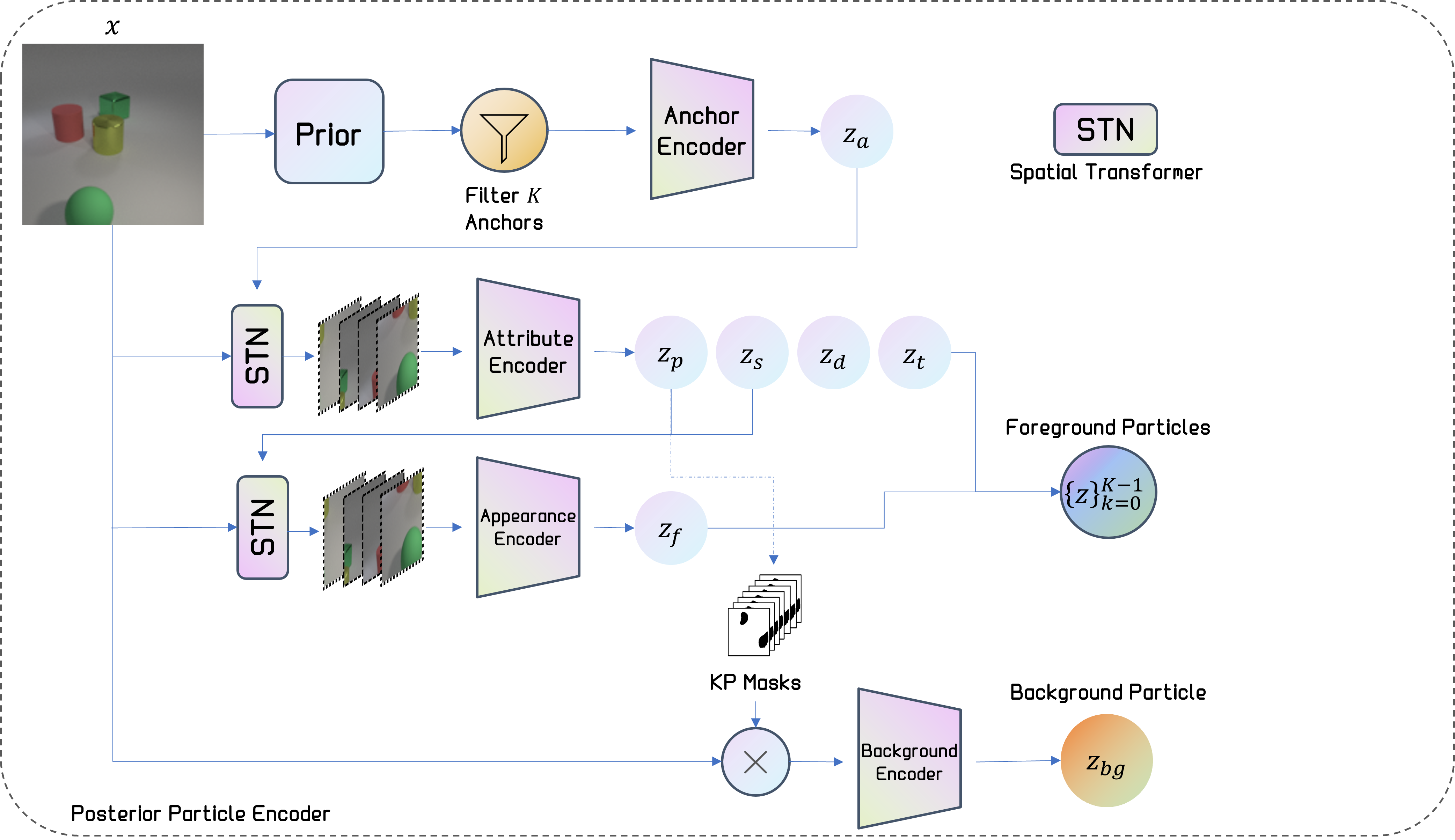
We compare DLPv2 to the original DLP on the Traffic and OBJ3D datasets in the single-image setting. As shown below, DLPv2 generates particles that exhibit stronger center-locking on objects.

