Video Prediction
Unsupervised object-centric video prediction with DDLP
- We compare DDLP to two SOTA object-centric models: G-SWM (patch-based model) and SlotFormer (slot-based model, “Comaprison” section).


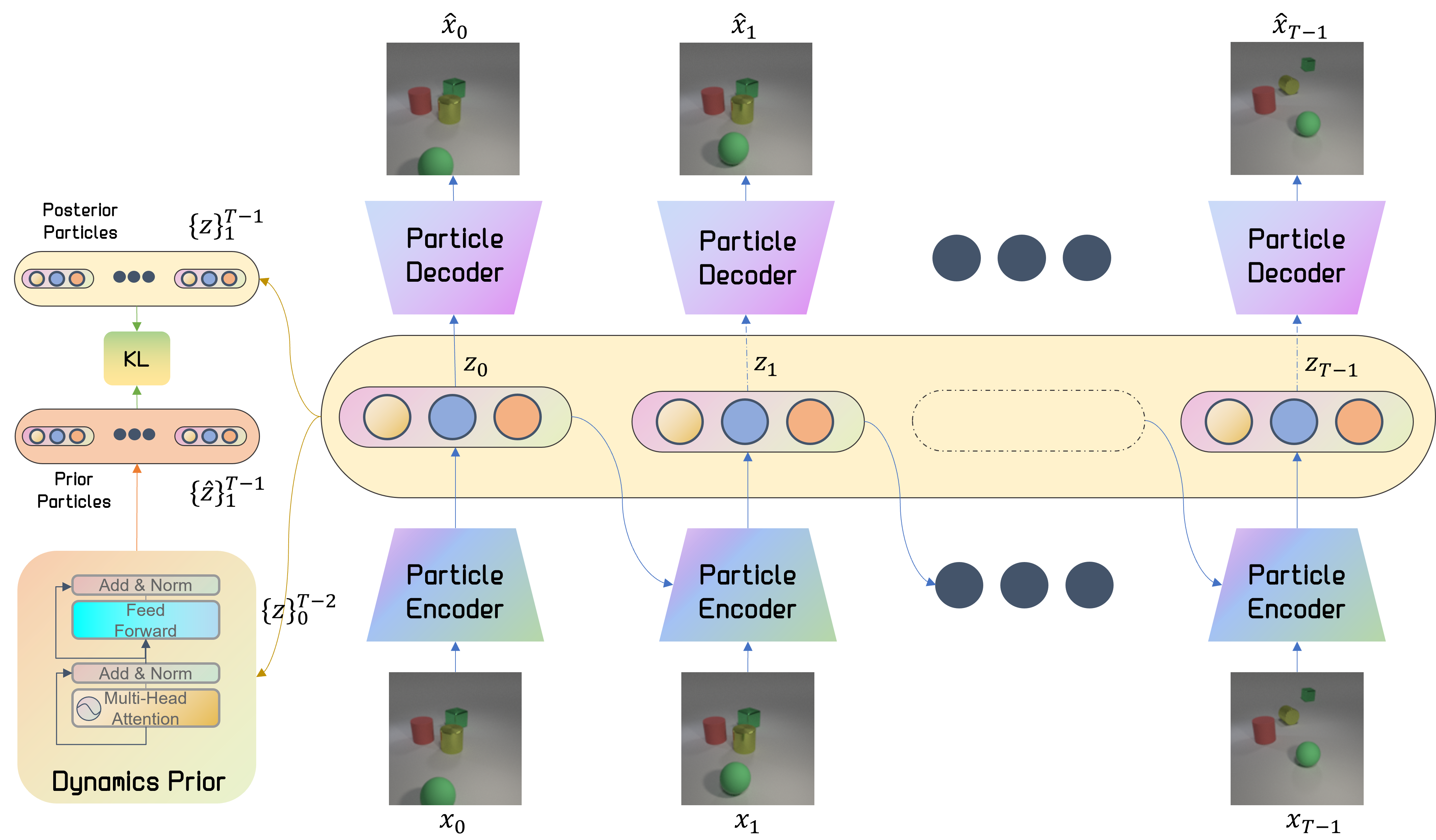
- Input frames \(\{x\}_0^{T-1}\).
- For each \(0\leq t \leq T-1\), a particle encoder produces the latent particle representation \(z_t\) given \(x_t\) and \(z_{t-1}\) – tracking the particles to induce consistency between frames.
- Each individual latent \(z_{t}\) is fed through the particle decoder to produce the reconstruction of frame \(\hat{x}_{t}\).
- A Transformer-based dynamics module (PINT - Particle Interaction Transformer) models the prior distribution parameters \(\{ \hat{z}\}_1^{T-1}\) given \(\{ z\}_0^{T-2}\).
- A pixel-wise reconstruction term minimizes the distance between the original frame \(x_t\) and decoded frame \(\hat{x}_{t}\), and A KL loss term minimizes the distance between the prior \(\{ \hat{z}\}_1^{T-1}\) and posterior \(\{ z\}_1^{T-1}\).
OBJ3D
More videos are available under the “What If…?” section.


Traffic




PHYRE




CLEVRER




Balls-Interaction




Failure Cases
- DDLP errs when new objects appear during the context window (CLEVRER)
- DDLP may deform objects in scenes with objects of varying scales (PHYRE)

